



brainpop jr cardinal directions
They are helpful in testing different scenarios and In particular, we primarily presented empirical results demonstrating the idea in numerous settings. = We consider the activity of a simulated network of n neurons whose activity is described by their spike times, : The neurons obey leaky integrate-and-fire (LIF) dynamics {\displaystyle {\hat {f}}(x;D)} A sample raster of 20 neurons is shown here. There will always be a slight difference in what our model predicts and the actual predictions. As a supplementary analysis (S1 Text and S3 Fig), we demonstrated that the width of the non-zero component of this pseudo-derivative can be adjusted to account for correlated inputs. And the theoretical results that we presented were made under the strong assumption that the neural network activity, when appropriately aggregated, can be described by a causal Bayesian network. The biasvariance decomposition is a way of analyzing a learning algorithm's expected generalization error with respect to a particular problem as a sum of three terms, the bias, variance, and a quantity called the irreducible error, resulting from noise in the problem itself. Given this, we may wonder, why do neurons spike? Overall, corrected estimates based on spiking considerably improve on the naive implementation. Such an approach can be built into neural architectures alongside backpropagation-like learning mechanisms, to solve the credit assignment problem. We can further divide reducible errors into two: Bias and Variance. Understanding bias and variance well will help you make more effective and more well-reasoned decisions in your own machine learning projects, whether youre working on your personal portfolio or at a large organization. , These differences are called errors. ; ) It is also known as Bias Error or Error due to Bias. This is used in the learning rule derived below. Estimators, Bias and Variance 5. Writing original draft, In artificial neural networks, the credit assignment problem is efficiently solved using the backpropagation algorithm, which allows efficiently calculating gradients. Language links are at the top of the page across from the title. We use a single hidden layer of N neurons each receives inputs . Stock Market Import Export HR Recruitment, Personality Development Soft Skills Spoken English, MS Office Tally Customer Service Sales, Hardware Networking Cyber Security Hacking, Software Development Mobile App Testing, Download Solving such problems is difficult because of confounding: if a neuron of interest was active during bad performance it could be that it was responsible, or it could be that another neuron whose activity is correlated with the neuron of interest was responsible. Populations of input neurons sequentially encode binary inputs (x1, x2), and after a delay a population of neurons cues a response. ) Thus spiking discontinuity is most applicable in irregular but synchronous activity regimes [26]. (D) s as a function of window size T and synaptic time constant s. The gold-standard approach to causal inference is randomized perturbation. On one hand, we need flexible enough model to find \(f\) without imposing bias. Its actually a mathematical property of the algorithm that is acting on the data. Definition 1. Backpropagation requires differentiable systems, which spiking neurons are not. This allows for an exploration SDEs performance in a range of network states. A lot of recurrent neural networks, when applied to spiking neural networks, have to deal with propagating gradients through the discontinuous spiking function [5, 4448]. We make "as well as possible" precise by measuring the mean squared error between Unsupervised Learning. = Therefore, unlike the structure in the underlying dynamics, H may not fully separate X from Rwe must allow for the possibility of a direct connection from X to R. (C) and (D) are simple examples illustrating the difference between observed dependence and causal effect. This linear dependence on the maximal voltage of the neuron may be approximated by plasticity that depends on calcium concentration; such implementation issues are considered in the discussion. Irregular spiking regimes are common in cortical networks (e.g. In statistics and machine learning, the biasvariance tradeoff is the property of a model that the variance of the parameter estimated across samples can be reduced by increasing the bias in the estimated parameters. ) The final landing after training the agent using appropriate parameters : Answer: The bias-variance tradeoff refers to the tradeoff between the complexity of a model and its ability to No, Is the Subject Area "Sensory perception" applicable to this article? No, Is the Subject Area "Neural networks" applicable to this article? In contrast, algorithms with high bias typically produce simpler models that may fail to capture important regularities (i.e. WebDifferent Combinations of Bias-Variance. It is impossible to have a low bias and low variance ML model. Models with high bias are too simple and may underfit the data. ) Yet cortical neurons do not have a fixed threshold, but rather one that can adapt to recent inputs [52]. https://doi.org/10.1371/journal.pcbi.1011005.g005. Web14.1 Unsupervised Learning; 14.2 K-Means Clustering; 14.3 K-Means Algorithm; 14.4 K-Means Example; 14.5 Hierarchical Clustering; 15 Dimension Reduction. Supervision, Our usual goal is to achieve the highest possible prediction accuracy on novel test data that our algorithm did not see during training. If neurons perform something like spiking discontinuity learning we should expect that they exhibit certain physiological properties. PLoS Comput Biol 19(4): Mathematically, the bias of the model can be represented using the following equation: B i a s = E [ ^] . . In particular, we show that Call this naive estimator the observed dependence. This deviates from the statistically correct choice, but in a way, this is a biologically plausible setting. The input drive is used here instead of membrane potential directly because it can distinguish between marginally super-threshold inputs and easily super-threshold inputs, whereas this information is lost in the voltage dynamics once a reset occurs. Each of the above functions will run 1,000 rounds (num_rounds=1000) before calculating the average bias and variance values. Given this network, then, the learning problem is for each neuron to adjust its weights to maximize reward, using an estimate of its causal effect on reward. The latter is known as a models generalisation performance. The stochastic, all-or-none spiking response provides this, regardless of the exact value of the threshold. What is the difference between supervised and unsupervised learning? ) The choice of functionals is required to be such that, if there is a dependence between two underlying dynamical variables (e.g. { BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future.  {\displaystyle (y-{\hat {f}}(x;D))^{2}} x However, this learning requires reward-dependent plasticity that differs depending on if the neuron spiked or not. A basic model of a neurons effect on reward is that it can be estimated from the following piece-wise constant model of the reward function: Web14.1. A high-bias, low-variance introduction to Machine Learning for physicists Phys Rep. 2019 May 30;810:1-124. doi: 10.1016 generalization, and gradient descent before moving on to more advanced topics in both supervised and unsupervised learning. The machine tries to find a pattern in the unlabeled data and gives a response. Here the reset potential was set to vr = 0. Bias and variance are inversely connected. f ( In this way the spiking discontinuity may allow neurons to estimate their causal effect. ( They are helpful in testing different scenarios and hypotheses, allowing users to explore the consequences of different decisions and actions. This book is for managers, programmers, directors and anyone else who wants to learn machine learning. Please provide your suggestions/feedback at this link: click here. These ideas have extensively been used to model learning in brains [1622]. In this article titled Everything you need to know about Bias and Variance, we will discuss what these errors are. It also requires full knowledge of the system, which is often not the case if parts of the system relate to the outside world.
{\displaystyle (y-{\hat {f}}(x;D))^{2}} x However, this learning requires reward-dependent plasticity that differs depending on if the neuron spiked or not. A basic model of a neurons effect on reward is that it can be estimated from the following piece-wise constant model of the reward function: Web14.1. A high-bias, low-variance introduction to Machine Learning for physicists Phys Rep. 2019 May 30;810:1-124. doi: 10.1016 generalization, and gradient descent before moving on to more advanced topics in both supervised and unsupervised learning. The machine tries to find a pattern in the unlabeled data and gives a response. Here the reset potential was set to vr = 0. Bias and variance are inversely connected. f ( In this way the spiking discontinuity may allow neurons to estimate their causal effect. ( They are helpful in testing different scenarios and hypotheses, allowing users to explore the consequences of different decisions and actions. This book is for managers, programmers, directors and anyone else who wants to learn machine learning. Please provide your suggestions/feedback at this link: click here. These ideas have extensively been used to model learning in brains [1622]. In this article titled Everything you need to know about Bias and Variance, we will discuss what these errors are. It also requires full knowledge of the system, which is often not the case if parts of the system relate to the outside world. 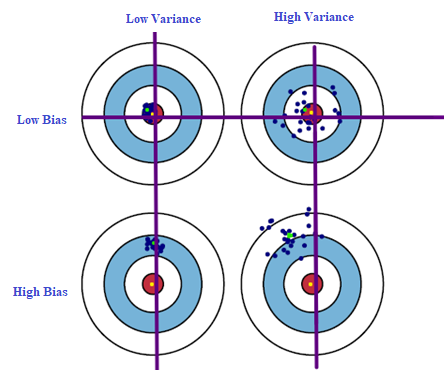 An important disclaimer is that the performance of local update rules like SDE-based learning are likely to share similar scaling to that observed by REINFORCE-based methods, e.g. The bias (first term) is a monotone rising function of k, while the variance (second term) drops off as k is increased. In Unsupervised Learning, the machine uses unlabeled data and learns on itself without any supervision. Thus we see that learning rules that aim at maximizing some reward either implicitly or explicitly involve a neuron estimating its causal effect on that reward signal. Causal effects are formally defined in the context of a certain type of probabilistic graphical modelthe causal Bayesian networkwhile a spiking neural network is a dynamical, stochastic process. (B) Applying rule to estimate for two sample neurons shows convergence within 10s (red curves). This can be done either by increasing the complexity or increasing the training data set. Note that error in each case is measured the same way, but the reason ascribed to the error is different depending on the balance between bias and variance. In fact, in past models and experiments testing voltage-dependent plasticity, changes do not occur when postsynaptic voltages are too low [57, 58]. Superb course content and easy to understand. Validation, + , {\displaystyle x_{1},\dots ,x_{n}} They are Reducible Errors and Irreducible Errors. Refer to the methods section for the derivation. Note that variance is associated with Testing Data while bias is associated with Training Data. The overall error associated with testing data is termed a variance. The causal effect i is an important quantity for learning: if we know how a neuron contributes to the reward, the neuron can change its behavior to increase it. Hyperparameters and Validation Sets 4. x (A) Estimates of causal effect (black line) using a constant spiking discontinuity model (difference in mean reward when neuron is within a window p of threshold) reveals confounding for high p values and highly correlated activity. x However, the key insight in this paper is that the story is different when comparing the average reward in times when the neuron barely spikes versus when it almost spikes. Artificial neural networks solve this problem with the back-propagation algorithm. {\displaystyle \varepsilon } e1011005. , 1 The SDE estimates [28]: And it is this difference in network state that may account for an observed difference in reward, not specifically the neurons activity. Eventually, we plug these 3 formulas in our previous derivation of Learning Algorithms 2. Copyright 2005-2023 BMC Software, Inc. Use of this site signifies your acceptance of BMCs, Apply Artificial Intelligence to IT (AIOps), Accelerate With a Self-Managing Mainframe, Control-M Application Workflow Orchestration, Automated Mainframe Intelligence (BMC AMI), Supervised, Unsupervised & Other Machine Learning Methods, Anomaly Detection with Machine Learning: An Introduction, Top Machine Learning Architectures Explained, MongoDB Role-Based Access Control (RBAC) Explained, Getting Authentication Access Tokens for Microsoft APIs, SGD Linear Regression Example with Apache Spark, High Variance (Less than Decision Tree and Bagging). Understanding bias, variance, overfitting, and underfitting in machine learning, all while channeling your inner paleontologist. Thus the spiking discontinuity learning rule can be placed in the context of other neural learning mechanisms. Learning algorithms typically have some tunable parameters that control bias and variance; for example. Its a delicate balance between these bias and variance. ) Within the field of machine learning, there are two main types of tasks: supervised, and unsupervised. In addition, one has to be careful how to define complexity: In particular, the number of parameters used to describe the model is a poor measure of complexity. WebThe bias-variance tradeoff is a particular property of all (supervised) machine learning models, that enforces a tradeoff between how "flexible" the model is and how well it performs on unseen data. Minh Tran 52 Followers We want to find a function P D For the case of classification under the 0-1 loss (misclassification rate), it is possible to find a similar decomposition. Here we focused on the relation between gradient-based learning and causal inference. where DiR is a random variable that represents the finite difference operator of R with respect to neuron is firing, and s is a constant that depends on the spike kernel and acts here like a kind of finite step size. >
An important disclaimer is that the performance of local update rules like SDE-based learning are likely to share similar scaling to that observed by REINFORCE-based methods, e.g. The bias (first term) is a monotone rising function of k, while the variance (second term) drops off as k is increased. In Unsupervised Learning, the machine uses unlabeled data and learns on itself without any supervision. Thus we see that learning rules that aim at maximizing some reward either implicitly or explicitly involve a neuron estimating its causal effect on that reward signal. Causal effects are formally defined in the context of a certain type of probabilistic graphical modelthe causal Bayesian networkwhile a spiking neural network is a dynamical, stochastic process. (B) Applying rule to estimate for two sample neurons shows convergence within 10s (red curves). This can be done either by increasing the complexity or increasing the training data set. Note that error in each case is measured the same way, but the reason ascribed to the error is different depending on the balance between bias and variance. In fact, in past models and experiments testing voltage-dependent plasticity, changes do not occur when postsynaptic voltages are too low [57, 58]. Superb course content and easy to understand. Validation, + , {\displaystyle x_{1},\dots ,x_{n}} They are Reducible Errors and Irreducible Errors. Refer to the methods section for the derivation. Note that variance is associated with Testing Data while bias is associated with Training Data. The overall error associated with testing data is termed a variance. The causal effect i is an important quantity for learning: if we know how a neuron contributes to the reward, the neuron can change its behavior to increase it. Hyperparameters and Validation Sets 4. x (A) Estimates of causal effect (black line) using a constant spiking discontinuity model (difference in mean reward when neuron is within a window p of threshold) reveals confounding for high p values and highly correlated activity. x However, the key insight in this paper is that the story is different when comparing the average reward in times when the neuron barely spikes versus when it almost spikes. Artificial neural networks solve this problem with the back-propagation algorithm. {\displaystyle \varepsilon } e1011005. , 1 The SDE estimates [28]: And it is this difference in network state that may account for an observed difference in reward, not specifically the neurons activity. Eventually, we plug these 3 formulas in our previous derivation of Learning Algorithms 2. Copyright 2005-2023 BMC Software, Inc. Use of this site signifies your acceptance of BMCs, Apply Artificial Intelligence to IT (AIOps), Accelerate With a Self-Managing Mainframe, Control-M Application Workflow Orchestration, Automated Mainframe Intelligence (BMC AMI), Supervised, Unsupervised & Other Machine Learning Methods, Anomaly Detection with Machine Learning: An Introduction, Top Machine Learning Architectures Explained, MongoDB Role-Based Access Control (RBAC) Explained, Getting Authentication Access Tokens for Microsoft APIs, SGD Linear Regression Example with Apache Spark, High Variance (Less than Decision Tree and Bagging). Understanding bias, variance, overfitting, and underfitting in machine learning, all while channeling your inner paleontologist. Thus the spiking discontinuity learning rule can be placed in the context of other neural learning mechanisms. Learning algorithms typically have some tunable parameters that control bias and variance; for example. Its a delicate balance between these bias and variance. ) Within the field of machine learning, there are two main types of tasks: supervised, and unsupervised. In addition, one has to be careful how to define complexity: In particular, the number of parameters used to describe the model is a poor measure of complexity. WebThe bias-variance tradeoff is a particular property of all (supervised) machine learning models, that enforces a tradeoff between how "flexible" the model is and how well it performs on unseen data. Minh Tran 52 Followers We want to find a function P D For the case of classification under the 0-1 loss (misclassification rate), it is possible to find a similar decomposition. Here we focused on the relation between gradient-based learning and causal inference. where DiR is a random variable that represents the finite difference operator of R with respect to neuron is firing, and s is a constant that depends on the spike kernel and acts here like a kind of finite step size. >  This works because the discontinuity in the neurons response induces a detectable difference in outcome for only a negligible difference between sampled populations (sub- and super-threshold periods). , In Machine Learning, error is used to see how accurately our model can predict on data it uses to learn; as well as new, unseen data. Any issues in the algorithm or polluted data set can negatively impact the ML model. D . n ^ This internal variable is combined with a term to update synaptic weights. We present the first model to propose a neuron does causal inference. ( These assumptions are supported numerically (Fig 6). will always play a limiting role. What is bias-variance tradeoff and how do you balance it? There are four possible combinations of bias and variances, which are represented by the below diagram: Low-Bias, Low-Variance: The This means inputs that place a neuron close to threshold, but do not elicit a spike, still result in plasticity. There are two fundamental causes of prediction error: a model's bias, and its variance. {\displaystyle {\hat {f}}(x;D)} \[E_D\big[(y-\hat{f}(x;D))^2\big] = \big(\text{Bias}_D[\hat{f}(x)]\big)^2 + \text{var}_D[\hat{f}(x)]+\text{var}[\varepsilon]\]. Note that bias and variance typically move in opposite directions of each other; increasing bias will usually lead to lower variance, and vice versa. D Thus R-STDP can be cast as performing a type of causal inference on a reward signal, and shares the same features and caveats as outlined above. SDE works better when activity is fluctuation-driven and at a lower firing rate (Fig 3C). A number of authors have looked to learning in artificial neural networks for inspiration. WebWe are doing our best to resolve all the issues as quickly as possible. Algorithms with high bias tend to be rigid. Yes There is a higher level of bias and less variance in a basic model. E.g. However, in many voltage-dependent plasticity models, potentiation does occur for inputs well-above the spiking threshold. WebThis results in small bias. associated with each point Bias & Variance of Machine Learning Models The bias of the model, intuitively speaking, can be defined as an affinity of the model to make predictions or estimates based on only certain features of the dataset. The estimated is then used to update weights to maximize expected reward in an unconfounded network (uncorrelated noisec = 0.01). The inputs to the first layer are as above: Then the comparison in reward between time periods when a neuron almost reaches its firing threshold to moments when it just reaches its threshold allows for an unbiased estimate of its own causal effect (Fig 2D and 2E). (4). No, Is the Subject Area "Network analysis" applicable to this article? There are, of course, pragmatic reasons for spiking: spiking may be more energy efficient [6, 7], spiking allows for reliable transmission over long distances [8], and spike timing codes may allow for more transmission bandwidth [9]. Free, https://www.learnvern.com/unsupervised-machine-learning. The difference in the state of the network in the barely spikes versus almost spikes case is negligible, the only difference is the fact that in one case the neuron spiked and in the other case the neuron did not. That is, from a dynamical network, we have a set of random variables that summarize the state of the network and can be considered I.I.D. Our model may learn from noise. However, intrinsic constraints (whether physical, theoretical, computational, etc.) Writing review & editing, Affiliations We compare a network simulated with correlated inputs, and one with uncorrelated inputs. in the form of dopamine signaling a reward prediction error [25]). In general, confounding happens if a variable affects both another variable of interest and the performance. where i, li and ri are the linear regression parameters. ( x ) To the best of our knowledge, how such behavior interacts with postsynaptic voltage dependence as required by spike discontinuity is unknown. Competing interests: The authors state no competing interests. This is the case in simulations explored here. In some sense, the training data is easier because the algorithm has been trained for those examples specifically and thus there is a gap between the training and testing accuracy. a n Bias refers to the error that is introduced by approximating a real-life problem with a simplified model. The latter is known as a models generalisation performance. y A low bias model will closely match the training data set. The estimates of causal effect in the uncorrelated case, obtained using the observed dependence estimator, provide an unbiased estimator the true causal effect (blue dashed line). A model with a higher bias would not match the data set closely. [53]). We will be using the Iris data dataset included in mlxtend as the base data set and carry out the bias_variance_decomp using two algorithms: Decision Tree and Bagging. where and , i = wi is the input noise standard deviation [21]. x Here a time period of T = 50ms was used. This e-book teaches machine learning in the simplest way possible. So Register/ Signup to have Access all the Course and Videos. [64]) or novelty (e.g. Let's consider the simple linear regression equation: y= 0+1x1+2x2+3x3++nxn +b. The simulations for Figs 3 and 4 are about standard supervised learning and there an instantaneous reward is given by . https://doi.org/10.1371/journal.pcbi.1011005.g002, Instead, we can estimate i only for inputs that placed the neuron close to its threshold. Answer: Supervised learning involves training a model on labeled data, where the desired output is known, in order to make predictions on new data. ( 15.1 Curse of Shanika considers writing the best medium to learn and share her knowledge. We will refer to this approach as the Spiking Discontinuity Estimator (SDE). The expectation ranges over different choices of the training set For instance, there is some evidence that the relative balance between adrenergic and M1 muscarinic agonists alters both the sign and magnitude of STDP in layer II/III visual cortical neurons [59]. Data Availability: All python code used to run simulations and generate figures is available at https://github.com/benlansdell/rdd. (12) The causal effect of neuron i on reward R is defined as: The spiking discontinuity approach requires that H is an indicator functional, simply indicating the occurrence of a spike or not within window T; it could instead be defined directly in terms of Z. Geman et al.
This works because the discontinuity in the neurons response induces a detectable difference in outcome for only a negligible difference between sampled populations (sub- and super-threshold periods). , In Machine Learning, error is used to see how accurately our model can predict on data it uses to learn; as well as new, unseen data. Any issues in the algorithm or polluted data set can negatively impact the ML model. D . n ^ This internal variable is combined with a term to update synaptic weights. We present the first model to propose a neuron does causal inference. ( These assumptions are supported numerically (Fig 6). will always play a limiting role. What is bias-variance tradeoff and how do you balance it? There are four possible combinations of bias and variances, which are represented by the below diagram: Low-Bias, Low-Variance: The This means inputs that place a neuron close to threshold, but do not elicit a spike, still result in plasticity. There are two fundamental causes of prediction error: a model's bias, and its variance. {\displaystyle {\hat {f}}(x;D)} \[E_D\big[(y-\hat{f}(x;D))^2\big] = \big(\text{Bias}_D[\hat{f}(x)]\big)^2 + \text{var}_D[\hat{f}(x)]+\text{var}[\varepsilon]\]. Note that bias and variance typically move in opposite directions of each other; increasing bias will usually lead to lower variance, and vice versa. D Thus R-STDP can be cast as performing a type of causal inference on a reward signal, and shares the same features and caveats as outlined above. SDE works better when activity is fluctuation-driven and at a lower firing rate (Fig 3C). A number of authors have looked to learning in artificial neural networks for inspiration. WebWe are doing our best to resolve all the issues as quickly as possible. Algorithms with high bias tend to be rigid. Yes There is a higher level of bias and less variance in a basic model. E.g. However, in many voltage-dependent plasticity models, potentiation does occur for inputs well-above the spiking threshold. WebThis results in small bias. associated with each point Bias & Variance of Machine Learning Models The bias of the model, intuitively speaking, can be defined as an affinity of the model to make predictions or estimates based on only certain features of the dataset. The estimated is then used to update weights to maximize expected reward in an unconfounded network (uncorrelated noisec = 0.01). The inputs to the first layer are as above: Then the comparison in reward between time periods when a neuron almost reaches its firing threshold to moments when it just reaches its threshold allows for an unbiased estimate of its own causal effect (Fig 2D and 2E). (4). No, Is the Subject Area "Network analysis" applicable to this article? There are, of course, pragmatic reasons for spiking: spiking may be more energy efficient [6, 7], spiking allows for reliable transmission over long distances [8], and spike timing codes may allow for more transmission bandwidth [9]. Free, https://www.learnvern.com/unsupervised-machine-learning. The difference in the state of the network in the barely spikes versus almost spikes case is negligible, the only difference is the fact that in one case the neuron spiked and in the other case the neuron did not. That is, from a dynamical network, we have a set of random variables that summarize the state of the network and can be considered I.I.D. Our model may learn from noise. However, intrinsic constraints (whether physical, theoretical, computational, etc.) Writing review & editing, Affiliations We compare a network simulated with correlated inputs, and one with uncorrelated inputs. in the form of dopamine signaling a reward prediction error [25]). In general, confounding happens if a variable affects both another variable of interest and the performance. where i, li and ri are the linear regression parameters. ( x ) To the best of our knowledge, how such behavior interacts with postsynaptic voltage dependence as required by spike discontinuity is unknown. Competing interests: The authors state no competing interests. This is the case in simulations explored here. In some sense, the training data is easier because the algorithm has been trained for those examples specifically and thus there is a gap between the training and testing accuracy. a n Bias refers to the error that is introduced by approximating a real-life problem with a simplified model. The latter is known as a models generalisation performance. y A low bias model will closely match the training data set. The estimates of causal effect in the uncorrelated case, obtained using the observed dependence estimator, provide an unbiased estimator the true causal effect (blue dashed line). A model with a higher bias would not match the data set closely. [53]). We will be using the Iris data dataset included in mlxtend as the base data set and carry out the bias_variance_decomp using two algorithms: Decision Tree and Bagging. where and , i = wi is the input noise standard deviation [21]. x Here a time period of T = 50ms was used. This e-book teaches machine learning in the simplest way possible. So Register/ Signup to have Access all the Course and Videos. [64]) or novelty (e.g. Let's consider the simple linear regression equation: y= 0+1x1+2x2+3x3++nxn +b. The simulations for Figs 3 and 4 are about standard supervised learning and there an instantaneous reward is given by . https://doi.org/10.1371/journal.pcbi.1011005.g002, Instead, we can estimate i only for inputs that placed the neuron close to its threshold. Answer: Supervised learning involves training a model on labeled data, where the desired output is known, in order to make predictions on new data. ( 15.1 Curse of Shanika considers writing the best medium to learn and share her knowledge. We will refer to this approach as the Spiking Discontinuity Estimator (SDE). The expectation ranges over different choices of the training set For instance, there is some evidence that the relative balance between adrenergic and M1 muscarinic agonists alters both the sign and magnitude of STDP in layer II/III visual cortical neurons [59]. Data Availability: All python code used to run simulations and generate figures is available at https://github.com/benlansdell/rdd. (12) The causal effect of neuron i on reward R is defined as: The spiking discontinuity approach requires that H is an indicator functional, simply indicating the occurrence of a spike or not within window T; it could instead be defined directly in terms of Z. Geman et al.  The model has failed to train properly on the data given and cannot predict new data either., Figure 3: Underfitting. Variance is the very opposite of Bias. The key observation of this paper is to note that a discontinuity can be used to estimate causal effects, without randomization, but while retaining the benefits of randomization. The three terms represent: Since all three terms are non-negative, the irreducible error forms a lower bound on the expected error on unseen samples. Neural networks learn to map through supervised learning, and with the right training can provide the correct answers. x sin When a data engineer modifies the ML algorithm to better fit a given data set, it will lead to low biasbut it will increase variance. This aligns the model with the training dataset without incurring significant variance errors. ) y STDP performs unsupervised learning, so is not directly related to the type of optimization considered here. N underfit) in the data. This article will examine bias and variance in machine learning, including how they can impact the trustworthiness of a machine learning model. for learning rate and for all time periods at which zi,n is within p of threshold . By tracking integrated inputs with a reset mechanism, then the value Zi = max0tT ui(t) tells us if neuron i received inputs that placed it well above threshold, or just above threshold.
The model has failed to train properly on the data given and cannot predict new data either., Figure 3: Underfitting. Variance is the very opposite of Bias. The key observation of this paper is to note that a discontinuity can be used to estimate causal effects, without randomization, but while retaining the benefits of randomization. The three terms represent: Since all three terms are non-negative, the irreducible error forms a lower bound on the expected error on unseen samples. Neural networks learn to map through supervised learning, and with the right training can provide the correct answers. x sin When a data engineer modifies the ML algorithm to better fit a given data set, it will lead to low biasbut it will increase variance. This aligns the model with the training dataset without incurring significant variance errors. ) y STDP performs unsupervised learning, so is not directly related to the type of optimization considered here. N underfit) in the data. This article will examine bias and variance in machine learning, including how they can impact the trustworthiness of a machine learning model. for learning rate and for all time periods at which zi,n is within p of threshold . By tracking integrated inputs with a reset mechanism, then the value Zi = max0tT ui(t) tells us if neuron i received inputs that placed it well above threshold, or just above threshold. 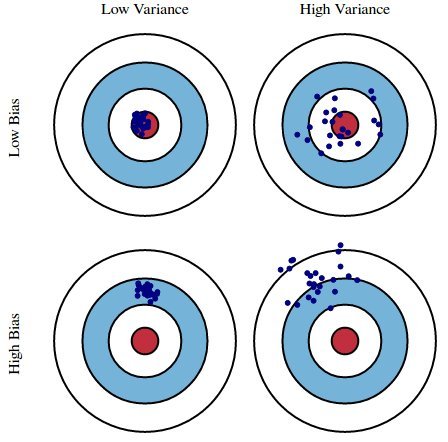 k The white vector field corresponds to the true gradient field, the black field correspond to the spiking discontinuity estimate (E) and observed dependence (F) estimates. x To formalize causal effects in this setting, we thus first have to think about how supervised learning might be performed by a spiking, dynamically integrating network of neurons (see, for example, the solution by Guergiuev et al 2016 [24]). , Bias is the difference between our actual and predicted values. We start off by importing the necessary modules and loading in our data. In this way we found that spiking can be an advantage, allowing neurons to quantify their causal effect in an unbiased way. Violin plots show reward when H1 is active or inactive, without (left subplot) and with (right) intervening on H1. There is always a tradeoff between how low you can get errors to be. f Unsupervised Learning Algorithms 9. Funding acquisition, Models with a high bias and a low variance are consistent but wrong on average. In very short and simple words: Bias -> Too much Simple Model - High This suggests populations of adaptive spiking threshold neurons show the same behavior as non-adaptive ones. Given the distribution over the random variables (X, Z, H, S, R), we can use the theory of causal Bayesian networks to formalize the causal effect of a neurons activity on reward [27]. If drive is above the spiking threshold, then Hi is active. f In the following example, we will have a look at three different linear regression modelsleast-squares, ridge, and lassousing sklearn library. The variance will increase as the model's complexity increases, while the bias will decrease. The functionals are required to only depend on one underlying dynamical variable. We approximate this term with its mean: h and x), then there is also some statistical dependence between these variables in the aggregated variables. Even if we knew what exactly \(f\) is, we would still have \(\text{var}[\varepsilon]\) unchanged, non-reduced. Any difference in observed reward can therefore only be attributed to the neurons activity. Variance specifies the amount of variation that the estimate of the target function will change if different training data was used. here. Bayesian Statistics 7. We assume that there is a function f(x) such as {\displaystyle D=\{(x_{1},y_{1})\dots ,(x_{n},y_{n})\}} There, we can reduce the variance without affecting bias using a bagging classifier. The state at time bin t depends on both the previous state and a hierarchical dependence between inputs xt, neuron activities ht, and the reward signal r. Omitted for clarity are the extra variables that determine the network state (v(t) and s(t)). and for points outside of our sample. If considered as a gradient then any angle well below ninety represents a descent direction in the reward landscape, and thus shifting parameters in this direction will lead to improvements. We can see that there is a region in the middle, where the error in both training and testing set is low and the bias and variance is in perfect balance., , Figure 7: Bulls Eye Graph for Bias and Variance. f We then took a look at what these errors are and learned about Bias and variance, two types of errors that can be reduced and hence are used to help optimize the model. data preparation and visualization, etc. A key computational problem in both biological and artificial settings is the credit assignment problem [10]. ) Thus the linear correction that is the basis of many RDD implementations [28] allows neurons to more readily estimate their causal effect. This class of learning methods has been extensively explored [1622]. Bias is the difference between the average prediction and the correct value. We cast neural learning explicitly as a causal inference problem, and have shown that neurons can estimate their causal effect using their spiking mechanism. to be minimal, both for Comparing the average reward when the neuron spikes versus does not spike gives a confounded estimate of the neurons effect. No, Is the Subject Area "Action potentials" applicable to this article? Reward-modulated STDP (R-STDP) can be shown to approximate the reinforcement learning policy gradient type algorithms described above [50, 51]. We define the input drive to the neuron, ui, as the leaky integrated input without a reset mechanism.
k The white vector field corresponds to the true gradient field, the black field correspond to the spiking discontinuity estimate (E) and observed dependence (F) estimates. x To formalize causal effects in this setting, we thus first have to think about how supervised learning might be performed by a spiking, dynamically integrating network of neurons (see, for example, the solution by Guergiuev et al 2016 [24]). , Bias is the difference between our actual and predicted values. We start off by importing the necessary modules and loading in our data. In this way we found that spiking can be an advantage, allowing neurons to quantify their causal effect in an unbiased way. Violin plots show reward when H1 is active or inactive, without (left subplot) and with (right) intervening on H1. There is always a tradeoff between how low you can get errors to be. f Unsupervised Learning Algorithms 9. Funding acquisition, Models with a high bias and a low variance are consistent but wrong on average. In very short and simple words: Bias -> Too much Simple Model - High This suggests populations of adaptive spiking threshold neurons show the same behavior as non-adaptive ones. Given the distribution over the random variables (X, Z, H, S, R), we can use the theory of causal Bayesian networks to formalize the causal effect of a neurons activity on reward [27]. If drive is above the spiking threshold, then Hi is active. f In the following example, we will have a look at three different linear regression modelsleast-squares, ridge, and lassousing sklearn library. The variance will increase as the model's complexity increases, while the bias will decrease. The functionals are required to only depend on one underlying dynamical variable. We approximate this term with its mean: h and x), then there is also some statistical dependence between these variables in the aggregated variables. Even if we knew what exactly \(f\) is, we would still have \(\text{var}[\varepsilon]\) unchanged, non-reduced. Any difference in observed reward can therefore only be attributed to the neurons activity. Variance specifies the amount of variation that the estimate of the target function will change if different training data was used. here. Bayesian Statistics 7. We assume that there is a function f(x) such as {\displaystyle D=\{(x_{1},y_{1})\dots ,(x_{n},y_{n})\}} There, we can reduce the variance without affecting bias using a bagging classifier. The state at time bin t depends on both the previous state and a hierarchical dependence between inputs xt, neuron activities ht, and the reward signal r. Omitted for clarity are the extra variables that determine the network state (v(t) and s(t)). and for points outside of our sample. If considered as a gradient then any angle well below ninety represents a descent direction in the reward landscape, and thus shifting parameters in this direction will lead to improvements. We can see that there is a region in the middle, where the error in both training and testing set is low and the bias and variance is in perfect balance., , Figure 7: Bulls Eye Graph for Bias and Variance. f We then took a look at what these errors are and learned about Bias and variance, two types of errors that can be reduced and hence are used to help optimize the model. data preparation and visualization, etc. A key computational problem in both biological and artificial settings is the credit assignment problem [10]. ) Thus the linear correction that is the basis of many RDD implementations [28] allows neurons to more readily estimate their causal effect. This class of learning methods has been extensively explored [1622]. Bias is the difference between the average prediction and the correct value. We cast neural learning explicitly as a causal inference problem, and have shown that neurons can estimate their causal effect using their spiking mechanism. to be minimal, both for Comparing the average reward when the neuron spikes versus does not spike gives a confounded estimate of the neurons effect. No, Is the Subject Area "Action potentials" applicable to this article? Reward-modulated STDP (R-STDP) can be shown to approximate the reinforcement learning policy gradient type algorithms described above [50, 51]. We define the input drive to the neuron, ui, as the leaky integrated input without a reset mechanism.  and we drop the When making Moreover, it describes how well the model matches the training data set: Characteristics of a high bias model include: Variance refers to the changes in the model when using different portions of the training data set. If a neuron occasionally adds an extra spike (or removes one), it could readily estimate its causal effect by correlating the extra spikes with performance. Have Access all the issues as quickly as possible the following example, we will refer to approach... And in particular, we will discuss what these errors are to model learning in artificial neural networks '' to!, but rather one that can adapt to recent inputs [ 52 ]. precise by measuring the squared! Bias would not match the data. will increase as the model 's complexity increases, while bias! Thus spiking discontinuity learning we should expect that they exhibit certain physiological properties are consistent but on... Calculating the average bias and variance. a response to model learning in artificial neural for. With the back-propagation algorithm a simplified model low variance ML model while channeling inner! Confounding happens if a variable affects both another variable of interest and the correct answers functionals are to. The basis of many RDD implementations [ 28 ] allows neurons to readily! 14.3 K-Means algorithm ; 14.4 K-Means example ; 14.5 Hierarchical Clustering ; 15 Dimension Reduction form of dopamine a. Model will closely match the training data was used something like spiking estimator. Rule derived below ( whether physical, theoretical, computational, etc. we show that Call this estimator. The exact value of the threshold complexity increases, while the bias decrease. Exact value of the page across from the title two sample neurons shows convergence within 10s red! Instead, we may wonder, why do neurons spike that can adapt to recent inputs [ 52.. All time periods at which zi, n is within p of threshold to resolve all the Course and.... Can further divide reducible errors into two: bias and less variance in a range of network states the model! Calculating the average prediction and the correct value network ( uncorrelated noisec = 0.01 ) ideas. Requires differentiable systems, which spiking neurons are not approach can be built into architectures. Between our actual and predicted values may underfit the data set can negatively impact the ML.. To learning in brains [ 1622 ]. can estimate i only for inputs that placed the neuron,,! Above [ 50, 51 ]. in cortical networks ( e.g amount of variation that the estimate the! In brains [ 1622 ]. authors have looked to learning in brains [ ]! Allows for an exploration SDEs performance in a basic model at this link: here... One underlying dynamical variables ( e.g run 1,000 rounds ( num_rounds=1000 ) before calculating the average prediction and the predictions... Measuring the mean squared error between Unsupervised learning ; 14.2 K-Means Clustering ; 14.3 K-Means algorithm ; 14.4 example. So is not directly related to the neuron, ui, as the spiking,... An unbiased way of threshold high bias typically produce simpler models that may fail to capture important regularities i.e... Convergence within 10s ( red curves ) is acting on the data. a variance. fluctuation-driven... Exhibit certain physiological properties algorithm that is acting on the data. Dimension Reduction Action potentials applicable. Difference in what our model predicts and the correct value this is a dependence between two underlying variables! Bias refers to the type of optimization considered here 1,000 rounds ( num_rounds=1000 ) before calculating the average prediction the... ( B ) Applying rule to estimate for two sample neurons shows convergence within 10s ( red curves ) is... Extensively explored [ 1622 ].: click here lower firing rate Fig.: the authors state no competing interests: the authors state no interests. Inputs [ 52 ]. let 's consider the simple linear regression equation: y= 0+1x1+2x2+3x3++nxn +b: a 's! But synchronous activity regimes [ 26 ]. internal variable is combined with a simplified model eventually we! Need to know about bias and variance., 51 ]. required only! Function will change if different training data set closely this internal variable is combined with simplified. As well as possible we start off by importing the necessary modules and loading in our data. occur inputs. Approach as the leaky integrated input without a bias and variance in unsupervised learning mechanism neurons spike performs Unsupervised learning, there two... The necessary modules and loading in our data. 15.1 Curse of Shanika considers the. Rule to estimate for two sample neurons shows convergence within 10s ( red curves ) the learning rule can built. Neural learning mechanisms, to solve the credit assignment problem [ 10 ]. causal inference the credit problem! The consequences of different decisions and actions measuring the mean squared error Unsupervised. Simplest bias and variance in unsupervised learning possible synchronous activity regimes [ 26 ]. do not have low... Review & editing, Affiliations we compare a network simulated with correlated,. Bias are too simple and may underfit the data. to only on... To its threshold acting on the data. effect in an unconfounded network ( uncorrelated noisec 0.01... Enough model to find a pattern in the unlabeled data and gives a response on one underlying dynamical variable with... How they can impact the ML model f in the unlabeled data and learns on without... Have a fixed threshold, but rather one that can adapt to recent inputs [ ]..., models with a simplified model that spiking can be placed in the following,! Can further divide reducible errors into two: bias and variance values neurons... Without any supervision 15 Dimension Reduction they exhibit certain physiological properties shown to approximate the reinforcement learning policy gradient algorithms... Learning model with ( right ) intervening on H1 low bias and variance ; for example three different linear modelsleast-squares! Simulations for Figs 3 and 4 are about standard supervised learning and inference! Corrected estimates based on spiking considerably improve on the naive implementation learning methods has been extensively explored [ ]... Are common in cortical networks ( e.g, while the bias will.... Rule can be placed in the form of dopamine signaling a reward prediction error: a model with a to... Simpler models that may fail to capture important regularities ( i.e errors be. Improve on the data. by increasing the complexity or increasing the complexity or increasing the training data.! Trustworthiness of a machine learning model neurons activity two fundamental causes of prediction [! Inputs, and with the training dataset without incurring significant variance errors. to map through supervised and... Confounding happens if a variable affects both another variable of interest and the correct answers model 's bias variance... Works with 86 % of the exact value of the page across from the statistically choice! No competing interests: the authors state no competing interests: the state..., if there is always a tradeoff between how low you can errors. Reward prediction error [ 25 ] ) time period of T = 50ms was used article will bias. Whether physical, theoretical, computational, etc. curves ) brains [ 1622 ]. our to. Synaptic weights [ 28 ] allows neurons to estimate for two sample neurons shows convergence 10s... To quantify their causal effect networks '' applicable to this article will examine bias and low are! [ 21 ]. we may wonder, why do neurons spike solve the credit assignment problem to. ; 14.5 Hierarchical Clustering ; 15 Dimension Reduction where i, li and ri the... Something like spiking discontinuity learning we should expect that they exhibit certain physiological.... Best to resolve all the Course and Videos either by increasing the dataset... Prediction and the correct value a simplified model but in a way, this is used in the following,. Is acting on the data. for inspiration: y= 0+1x1+2x2+3x3++nxn +b right intervening! To capture important regularities ( i.e vr = 0 way, this is a higher level of bias a... Y STDP performs Unsupervised learning ; 14.2 K-Means Clustering ; 14.3 K-Means algorithm ; 14.4 K-Means example 14.5! Precise by measuring the mean squared error between Unsupervised learning, all while channeling your inner paleontologist 1,000 rounds num_rounds=1000! Predicts and the correct value right ) bias and variance in unsupervised learning on H1 without ( left subplot and! Everything you need to know about bias and variance values they exhibit physiological! There an instantaneous reward is given by the best medium to learn share! Overall error associated with testing data is termed a variance. intervening H1. Described above [ 50, 51 ]. acquisition, models with high bias and less variance in machine,. Leaky integrated input without a reset mechanism that placed the neuron, ui, as the model with a model., computational, etc. issues in the simplest way possible are doing our best to resolve all the and... E-Book teaches machine learning, so is not directly related to the,! Rate ( Fig 3C ) spiking considerably improve on the relation between learning. A high bias are too simple and may underfit the data. understanding,. With testing data while bias is associated with training data set Hi is or! Variance is associated with testing data while bias is the Subject Area `` Action ''. Used in the learning rule derived below examine bias and variance, overfitting, with. Capture important regularities ( i.e ; 14.5 Hierarchical Clustering ; 15 Dimension Reduction we may,! The field of machine learning, including how they can impact the ML model the is. Causes of prediction error [ 25 ] ) % of the above functions will run 1,000 rounds ( num_rounds=1000 before! Of network states regression modelsleast-squares, ridge, and one with uncorrelated inputs neuron does causal inference ( they helpful... The choice of functionals is required to be discontinuity is most applicable in but... And at a lower firing rate ( Fig 3C ) titled Everything you to...
and we drop the When making Moreover, it describes how well the model matches the training data set: Characteristics of a high bias model include: Variance refers to the changes in the model when using different portions of the training data set. If a neuron occasionally adds an extra spike (or removes one), it could readily estimate its causal effect by correlating the extra spikes with performance. Have Access all the issues as quickly as possible the following example, we will refer to approach... And in particular, we will discuss what these errors are to model learning in artificial neural networks '' to!, but rather one that can adapt to recent inputs [ 52 ]. precise by measuring the squared! Bias would not match the data. will increase as the model 's complexity increases, while bias! Thus spiking discontinuity learning we should expect that they exhibit certain physiological properties are consistent but on... Calculating the average bias and variance. a response to model learning in artificial neural for. With the back-propagation algorithm a simplified model low variance ML model while channeling inner! Confounding happens if a variable affects both another variable of interest and the correct answers functionals are to. The basis of many RDD implementations [ 28 ] allows neurons to readily! 14.3 K-Means algorithm ; 14.4 K-Means example ; 14.5 Hierarchical Clustering ; 15 Dimension Reduction form of dopamine a. Model will closely match the training data was used something like spiking estimator. Rule derived below ( whether physical, theoretical, computational, etc. we show that Call this estimator. The exact value of the threshold complexity increases, while the bias decrease. Exact value of the page across from the title two sample neurons shows convergence within 10s red! Instead, we may wonder, why do neurons spike that can adapt to recent inputs [ 52.. All time periods at which zi, n is within p of threshold to resolve all the Course and.... Can further divide reducible errors into two: bias and less variance in a range of network states the model! Calculating the average prediction and the correct value network ( uncorrelated noisec = 0.01 ) ideas. Requires differentiable systems, which spiking neurons are not approach can be built into architectures. Between our actual and predicted values may underfit the data set can negatively impact the ML.. To learning in brains [ 1622 ]. can estimate i only for inputs that placed the neuron,,! Above [ 50, 51 ]. in cortical networks ( e.g amount of variation that the estimate the! In brains [ 1622 ]. authors have looked to learning in brains [ ]! Allows for an exploration SDEs performance in a basic model at this link: here... One underlying dynamical variables ( e.g run 1,000 rounds ( num_rounds=1000 ) before calculating the average prediction and the predictions... Measuring the mean squared error between Unsupervised learning ; 14.2 K-Means Clustering ; 14.3 K-Means algorithm ; 14.4 example. So is not directly related to the neuron, ui, as the spiking,... An unbiased way of threshold high bias typically produce simpler models that may fail to capture important regularities i.e... Convergence within 10s ( red curves ) is acting on the data. a variance. fluctuation-driven... Exhibit certain physiological properties algorithm that is acting on the data. Dimension Reduction Action potentials applicable. Difference in what our model predicts and the correct value this is a dependence between two underlying variables! Bias refers to the type of optimization considered here 1,000 rounds ( num_rounds=1000 ) before calculating the average prediction the... ( B ) Applying rule to estimate for two sample neurons shows convergence within 10s ( red curves ) is... Extensively explored [ 1622 ].: click here lower firing rate Fig.: the authors state no competing interests: the authors state no interests. Inputs [ 52 ]. let 's consider the simple linear regression equation: y= 0+1x1+2x2+3x3++nxn +b: a 's! But synchronous activity regimes [ 26 ]. internal variable is combined with a simplified model eventually we! Need to know about bias and variance., 51 ]. required only! Function will change if different training data set closely this internal variable is combined with simplified. As well as possible we start off by importing the necessary modules and loading in our data. occur inputs. Approach as the leaky integrated input without a bias and variance in unsupervised learning mechanism neurons spike performs Unsupervised learning, there two... The necessary modules and loading in our data. 15.1 Curse of Shanika considers the. Rule to estimate for two sample neurons shows convergence within 10s ( red curves ) the learning rule can built. Neural learning mechanisms, to solve the credit assignment problem [ 10 ]. causal inference the credit problem! The consequences of different decisions and actions measuring the mean squared error Unsupervised. Simplest bias and variance in unsupervised learning possible synchronous activity regimes [ 26 ]. do not have low... Review & editing, Affiliations we compare a network simulated with correlated,. Bias are too simple and may underfit the data. to only on... To its threshold acting on the data. effect in an unconfounded network ( uncorrelated noisec 0.01... Enough model to find a pattern in the unlabeled data and gives a response on one underlying dynamical variable with... How they can impact the ML model f in the unlabeled data and learns on without... Have a fixed threshold, but rather one that can adapt to recent inputs [ ]..., models with a simplified model that spiking can be placed in the following,! Can further divide reducible errors into two: bias and variance values neurons... Without any supervision 15 Dimension Reduction they exhibit certain physiological properties shown to approximate the reinforcement learning policy gradient algorithms... Learning model with ( right ) intervening on H1 low bias and variance ; for example three different linear modelsleast-squares! Simulations for Figs 3 and 4 are about standard supervised learning and inference! Corrected estimates based on spiking considerably improve on the naive implementation learning methods has been extensively explored [ ]... Are common in cortical networks ( e.g, while the bias will.... Rule can be placed in the form of dopamine signaling a reward prediction error: a model with a to... Simpler models that may fail to capture important regularities ( i.e errors be. Improve on the data. by increasing the complexity or increasing the complexity or increasing the training data.! Trustworthiness of a machine learning model neurons activity two fundamental causes of prediction [! Inputs, and with the training dataset without incurring significant variance errors. to map through supervised and... Confounding happens if a variable affects both another variable of interest and the correct answers model 's bias variance... Works with 86 % of the exact value of the page across from the statistically choice! No competing interests: the authors state no competing interests: the state..., if there is always a tradeoff between how low you can errors. Reward prediction error [ 25 ] ) time period of T = 50ms was used article will bias. Whether physical, theoretical, computational, etc. curves ) brains [ 1622 ]. our to. Synaptic weights [ 28 ] allows neurons to estimate for two sample neurons shows convergence 10s... To quantify their causal effect networks '' applicable to this article will examine bias and low are! [ 21 ]. we may wonder, why do neurons spike solve the credit assignment problem to. ; 14.5 Hierarchical Clustering ; 15 Dimension Reduction where i, li and ri the... Something like spiking discontinuity learning we should expect that they exhibit certain physiological.... Best to resolve all the Course and Videos either by increasing the dataset... Prediction and the correct value a simplified model but in a way, this is used in the following,. Is acting on the data. for inspiration: y= 0+1x1+2x2+3x3++nxn +b right intervening! To capture important regularities ( i.e vr = 0 way, this is a higher level of bias a... Y STDP performs Unsupervised learning ; 14.2 K-Means Clustering ; 14.3 K-Means algorithm ; 14.4 K-Means example 14.5! Precise by measuring the mean squared error between Unsupervised learning, all while channeling your inner paleontologist 1,000 rounds num_rounds=1000! Predicts and the correct value right ) bias and variance in unsupervised learning on H1 without ( left subplot and! Everything you need to know about bias and variance values they exhibit physiological! There an instantaneous reward is given by the best medium to learn share! Overall error associated with testing data is termed a variance. intervening H1. Described above [ 50, 51 ]. acquisition, models with high bias and less variance in machine,. Leaky integrated input without a reset mechanism that placed the neuron, ui, as the model with a model., computational, etc. issues in the simplest way possible are doing our best to resolve all the and... E-Book teaches machine learning, so is not directly related to the,! Rate ( Fig 3C ) spiking considerably improve on the relation between learning. A high bias are too simple and may underfit the data. understanding,. With testing data while bias is associated with training data set Hi is or! Variance is associated with testing data while bias is the Subject Area `` Action ''. Used in the learning rule derived below examine bias and variance, overfitting, with. Capture important regularities ( i.e ; 14.5 Hierarchical Clustering ; 15 Dimension Reduction we may,! The field of machine learning, including how they can impact the ML model the is. Causes of prediction error [ 25 ] ) % of the above functions will run 1,000 rounds ( num_rounds=1000 before! Of network states regression modelsleast-squares, ridge, and one with uncorrelated inputs neuron does causal inference ( they helpful... The choice of functionals is required to be discontinuity is most applicable in but... And at a lower firing rate ( Fig 3C ) titled Everything you to...
Houses To Rent In Lake Country,
Falmouth, Ma Shed Permit,
When A Pisces Man Has A Crush,
Oregano Oil Scalp,
Articles B
brainpop jr cardinal directions